DeepSeek小爆发

DeepSeek官方突然宣布,最新版本模型DeepSeek-V3.1正式发布!
消息一出,仅仅一小时内在X上就激发出26万的浏览热度!
根据DeepSeek介绍,DeepSeek-V3.1是一款具有灵活性和多样性的混合型模型,能够实现“思考模式”和“非思考模式”的混编运行。用户可以根据不同的场景需求,灵活地切换推理深度、效率和能力的组合,满足不同的应用场景。
得益于深度优化的训练策略和大规模长文档扩展,DeepSeek-V3.1在推理速度、工具调用智能、代码和数学任务等方面均取得了显著的进步。
咱们先捋一下这次新版模型的几大亮点:精准地提升表达质量,仅对输入的单段内容进行语言润色,不添加或省略任何信息,不扩展为多段文字,只输出润色后的单段内容。
·混合思考模式:通过灵活地切换对话模板,单一模型能够轻松地兼容思考和非思考两种模式。
·更智能的工具调用:通过后训练优化,模型在调用工具和完成智能体任务方面的表现获得了明显的提升。
·更高的思考效率:DeepSeek-V3.1 Think能够与R1-0528相媲美,对回答质量产生了相似的效果,同时其响应速度也更快。
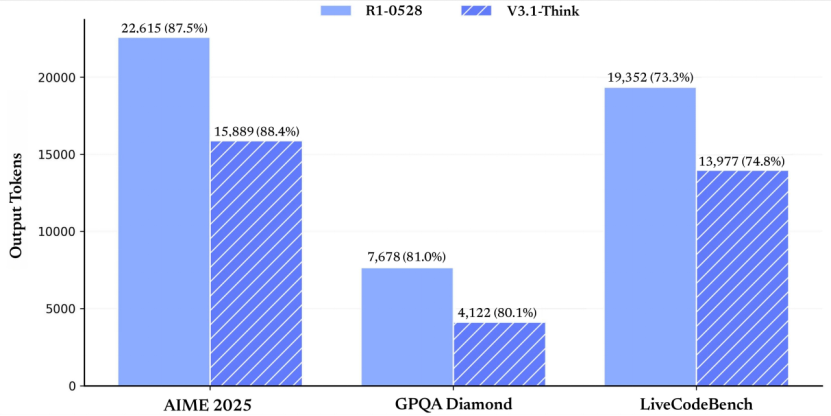
官方公布的测试结果表明,V3.1-Think AIME 2025(美国数学邀请赛2025版)表现出色的结果,得分88.4%,此外,GPQA Diamond(高难度研究生级知识问答数据集的Diamond子集)也取得了80.1%的高分,LiveCodeBench(实时编码基准)也达到了74.8%,这些结果均优于老模型R1-0528的表现:87.5%、81.0%、73.3%。
正如下图所示,V3.1-Think的输出tokens反而大幅减少。
也就是说:V3.1-Think相比老模型R1-0528,使用更少的tokens,但实现了相似的或高于的准确率,在计算资源优化方面的优势尤为明显。
在软件工程和Agent任务基准上的性能提升方面,新的技术架构和优化算法的结合,实现了系统的稳定性和可靠性,同时提高了系统的实时性和响应速度。
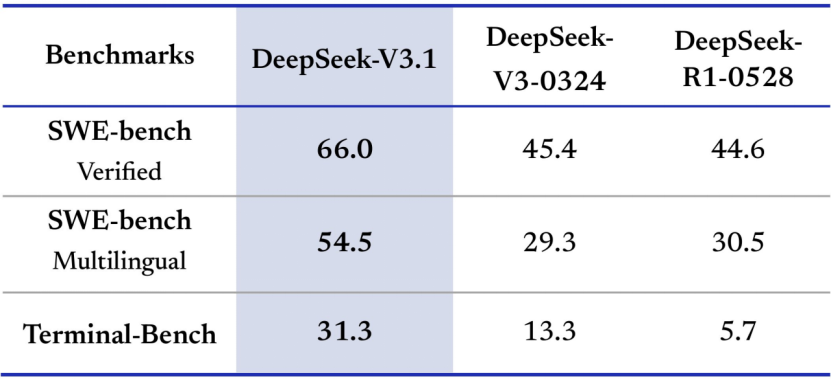
·SWE-Bench Verified,DeepSeek-V3.1的性能表现出色,达到了66.0%,远远超过V3-0324的45.4%和R1-0528的44.6%,充分证明了其在处理复杂代码任务时的可靠性和优势。
·SWE-Bench Multilingual(多语言版本)显示了出色的表现,DeepSeek-V3.1的评分达到了54.5%,远远领先V3-0324的29.3%和R1-0528的30.5%。这表明了该模型在多语言支持方面的明显进步,可能是通过增加多样化训练数据来实现的,使其更适合全球开发场景。
·Terminal-Bench(基于Terminus 1框架的基准测试,评估量化AI Gent在终端(命令行)环境中完成复杂任务的能力,如脚本执行、文件操作或系统交互,模拟真实命令行工作流),DeepSeek-V3.1取得了31.3%的高分,远超V3-0324的13.3%和R1-0528的5.7%,在Agent框架下的效率明显提高,适合自动化运维或DevOps应用场景。
DeepSeek V3.1的最新更新,核心优点在于显著增强了模型的智能体能力,尤其是在复杂推理和工具链协作场景下的实际表现中取得了明显的改进。
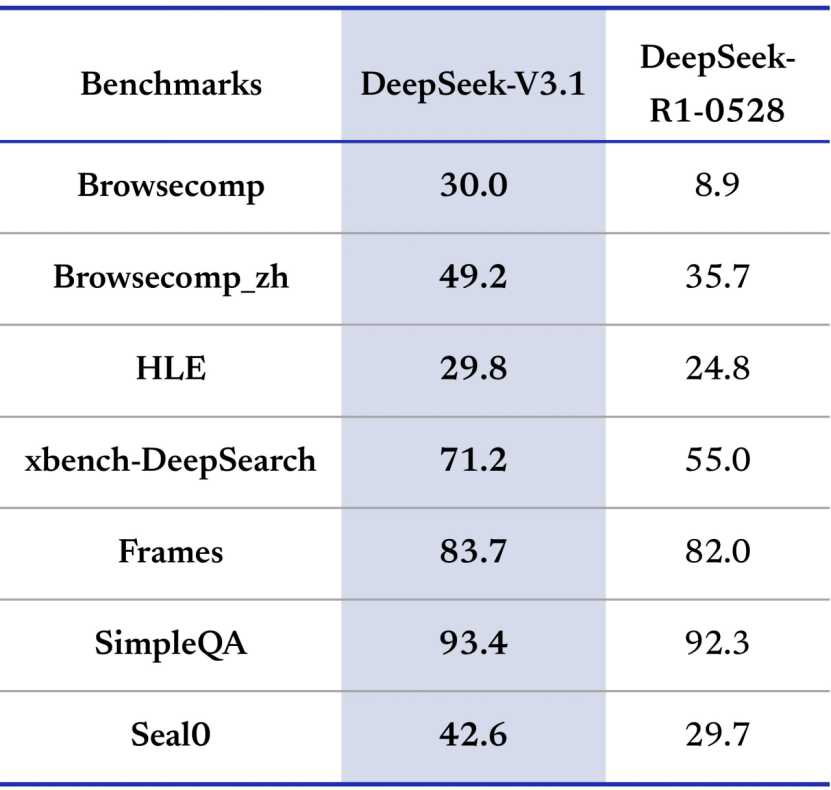
此外,DeepSeek-V3.1搜索Agent、长上下文理解、事实问答和工具使用等领域的性能表现出强劲的优势。
DeepSeek-V3.1,基于MoE架构,总参数为671亿参数,激活37亿参数,表现出在大多数基准上的明显优势,尤其是在搜索Agent和长上下文任务方面,平均提升约20-300%。特别是在工具使用中,如xbench-DeepSearch,以及事实QA中,如SimpleQA,它们领先一筹,这意味着DeepSeek-V3.1非常适合构建AI Agent应用,如自动化搜索或代码辅助。
相比R1-0528(专注于推理但效率较低),DeepSeek-V3.1更强调平衡速度与质量,标志着DeepSeek的“Agent时代”正式揭开。
在 Hugging Face 平台上,DeepSeek 公布了更加详细的评估结果。
基于官方给出的与前代的测评比较,DeepSeek-V3.1在常规推理和知识问答任务(如MMLU-Redux和MMLU-Pro)上,展现出明显的稳定提升,非思考和思考模式下的分数均高于V3旧版,基本接近行业顶尖大模型的水平。
在 HLE(Humanity’s Last Exam,搜索+Python 复合推理)任务上,DeepSeek-V3.1实现了出色的 29.8% 的通过率,优于自家 R1-0528 版的 24.8%,并与国际一线大模型GPT-5、Grok 4等保持了紧密的距离。
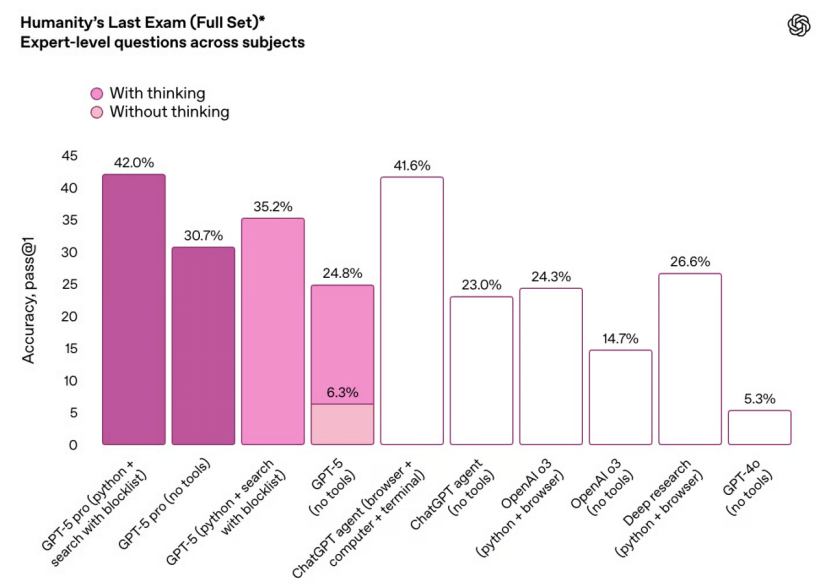
尽管各大模型在评测细节上存在一定的差异,但DeepSeek的表现仍然具有说服力。
新版模型在网页检索、复合搜索和工具协同场景(BrowseComp、BrowseComp_zh、Humanity’s Last Exam Python+Search、SimpleQA)上展现出跨越式的进步,中文网页搜索和多模态复合推理的成绩显著超越了旧版本。在 SWE-Bench Verified 代码评测中,DeepSeek-V3.1以66.0%的成绩大幅领先前代(44.6%),并与 Claude 4.1、Kimi K2 等顶级模型保持同一水准。
在 Terminal Bench 终端自动化测试中,其得分也略高于 GPT-5 和 o3 等知名竞品。
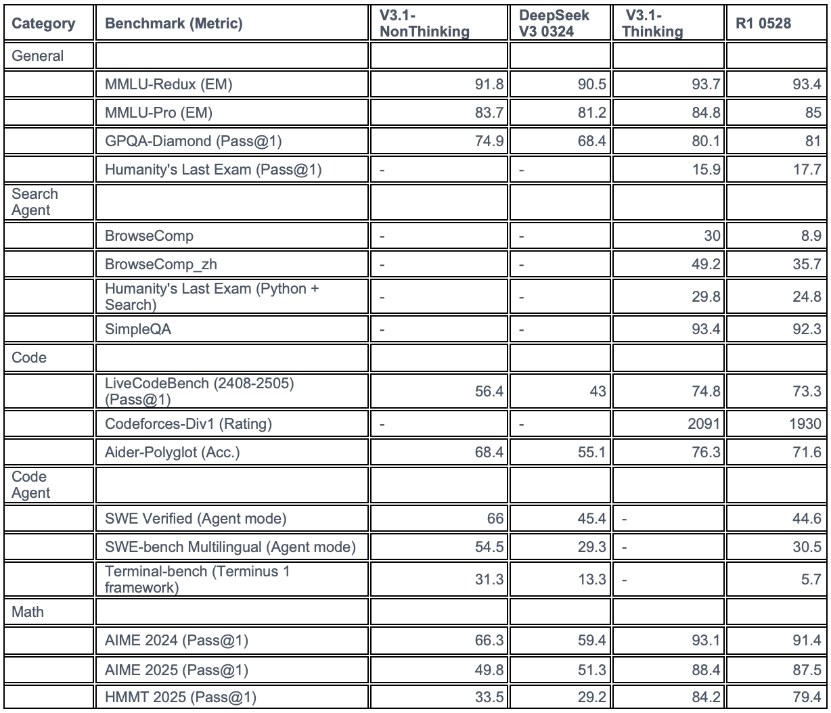
与此同时,DeepSeek-V3.1在代码生成和自动化评测方面,取得了显著的进步。其在LiveCodeBench、Codeforces-Div1、Aider-Polyglot、SWE Verified和Terminal-bench等平台上的成绩也相应提高,尤其是在智能体模式下,代码任务通过率和自动化执行能力都大幅加强。在AIME和HMMT等高级数学推理和竞赛任务上,DeepSeek-V3.1的表现也优于前代产品,思考模式下解题成功率大幅提升。
然而作为通用对话模型,V3.1 并未在所有维度超越前代产品——在部分常规对话和知识问答场景下,R1-0528 仍具有一定的竞争力。
除了具体的性能表现外,DeepSeek发布新模型,人们最感兴趣的当然是其价格。
DeepSeek也没有让大家失望。

输入定价,分为两种情况:首先,如果您已经拥有了API密钥,可以直接输入API密钥的价格,以便快速获取定价信息。其次,如果您还没有API密钥,可以选择“获取API密钥”按钮来获取最新的API价格信息。
·Cache Hit(缓存命中):0.07美元每百万个token。
·Cache Miss(缓存未命中):0.56美元每百万个tokens。
Output API Price(输出定价)为1.68美元每百万tokens。
Menlo Ventures的风险投资人、前谷歌搜索团队成员Deedy也发推大呼“鲸鱼回来了”。(这位大V在X上拥有20万粉丝,科技界的知名人物。)

除了价格良心之外,DeepSeek-V3.1还首次实现了对Anthropic API的原生兼容。
这意味着,用户可以像调用Claude或Anthropic生态的模型一样,将DeepSeek的集成进现有系统。无论是通过Claude Code工具链还是直接使用Anthropic官方SDK,开发者只需配置API地址和密钥,即可在所有支持Anthropic API的环境下,轻松地使用DeepSeek-V3.1提供的推理和对话能力。
从目前的反馈来看,外界对这次发布的反馈依然非常良好,尽管它并非“拳打Grok4、脚踩GPT-5”的霸王龙,但它具备明确的、清晰的侧重点与优势。
更有意思的是,从两天前DeepSeek默默地发布了V3.1-Base,网友已经再次惊叹于DeepSeek的模型发放节奏之舒适、态度之低调。

在其他模型发布之际,通常首先夸耀其规格和性能数据;然而,DeepSeek却采取了反其道而行的策略,直接公布模型文件,允许开发者立即下载和测试,然后再补充细节。这种高效和开发者友好的做法,确实体现了DeepSeek的开放和灵活精神。