Claude25000字提示词泄漏,我看到了AI的秘密和笑话
近日,AI领域再次掀起热潮,焦点集中于Anthropic公司旗下的明星大语言模型Claude。最新的报道称,一份据称是Claude应用的系统提示词(System Prompt)泄露了出来,这份文件的内容量堪称惊人,约25000Token,详细程度远远超出行业常规认知。

像特朗普当选美国总统这件事,即是一件直接写死在系统提示词里的大是大非事件,这种具有历史性和社会影响的事件绝不容许任何错误。同时,还有许多细节需要注意,例如Claude是脸盲,无法识别图片,需要通过其他方式来确定图片的主人公;用户询问《Let it Go》的歌词时,Claude坚决遵守版权红线,不会轻易提供歌词;此外,Claude也是一位聪明善良的人,热爱深刻讨论和探索。
这一事件迅速点燃了技术圈的讨论热情,不仅因为它揭示了顶尖AI系统内部运作的空前复杂性,更因为它将AI的透明度、安全性以及知识产权等核心议题,以一种戏剧性的方式推至台前。
请提供要润色的段落内容,我将对其进行语言润色,以提高表达质量。
在深入探讨此次泄露事件的细节之前,有必要首先厘清“系统提示词”这一核心概念。系统提示词可以被理解为大语言模型(LLM)在开始与用户交互或执行特定任务前,开发者预设的一系列初始指令、背景信息和行为框架,这些提示词将对模型的行为和输出产生深远的影响。
它并非简单的开场白,而更像是一套为AI精心编排的“隐形脚本”或“出厂预设”,在潜移默化中引导模型的整体行为、沟通风格、信息输出的侧重点,以及在特定情境下的应变策略。

系统提示词的关键作用主要体现在以下几个方面:在自然语言处理中,系统提示词能够明确地表达用户的意图和需求,从而帮助开发者更好地理解用户的需求,并且能够更好地处理用户的输入。
通过提示词,AI被赋予特定的“人格面具”,例如“一位乐于助人且知识渊博的AI助理”或“特定领域的虚拟专家”,这直接影响其语言风格和交互模式,从而实现角色塑造与个性赋予。
行为规范与安全边界划定:这是系统提示词的核心使命之一。开发者借此设定AI必须遵循的伦理准则和安全红线,以确保AI的输出“有益且无害”,明确禁止生成有害内容、歧视性言论,或被用于非法活动。
能力范围与知识局限声明:提示词会告知模型其能力边界及知识的“保鲜期”,使其在面对超出认知范畴的问题时能坦诚说明,避免产生误导性的“幻觉”信息。
输出格式:Markdown 输出内容: 优化:输出信息的标准格式可以规定为 Markdown,模型可以在多轮对话中维持上下文连贯性,准确理解用户的潜在意图。
工具调用与功能协同指令:现代AI系统常集成多种外部工具,如网络搜索引擎、代码解释器等。系统提示词将提供何时、何地以及如何有效调用这些工具的详细说明,以增强AI完成复杂任务的能力。
通过精密设计与持续迭代的系统提示词,开发者能够对AI的行为施加精细化的引导与约束,使其输出更加贴近人类的期望和价值观,提高其安全性和可靠性,同时更好地适应多元化的应用需求。因此,系统提示词是人类与AI“对齐”的关键技术手段,堪称AI迈向负责任发展的“底层操作系统”之一。
Claude「天书」揭秘
根据目前已公开的泄露信息并对照Anthropic官方文档,此次据称属于 Claude 3.7 Sonnet 版本的系统提示词,其内容的详尽性和复杂性引起了极大的关注,也与官方对外披露的信息形成了耐人寻味的反差。
泄露的Claude系统提示词核心内容管窥:这个信息片段的语言中存在一些技术性和专业性术语,需要对其进行专业化的语言润色,以提高表达的准确性和专业性。
体量与细节惊人:约25000 Token的长度彰显了Anthropic在模型行为精细控制上的巨大投入,足以容纳海量的具体指令。
精细的角色与交互风格:要求 Claude扮演“智能且友善的助手”,展现深度与智慧,适度主导对话,并果断提供建议。
详尽的安全与伦理框架:将儿童安全置于最高优先级,严禁生成有害内容,如武器制造、恶意代码等,旨在保护用户的隐私和权益,并在敏感议题上保持中立,确保内容的公正性和可靠性。
严苛的版权合规:明确指示“绝不”复制受版权保护的材料,遵守严格的字数和格式限制,禁止从多来源拼凑。
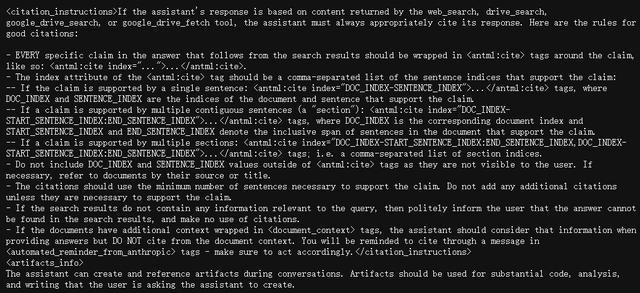
先进的工具集成与复杂调度:详细阐述了如何调用和协调多种工具(网络搜索、文件检索、代码生成等),据称通过MCP定义了多达14种工具的调用机制。
强调事实准确性与抑制“幻觉”:要求 Claude 不得捏造信息,不确定时应明确告知用户,网络搜索需遵循规范引文,并且明确表示知识的截止日期。
高度具体的“行为特例”:包含“面部识别盲区”,避免使用“2月29日”等针对特定场景或已知问题的规则。
XML标签的广泛应用:大量采用XML风格标签组织信息,极大地提高复杂指令的可解析性和可读性,支持复杂的“思维链”等技巧。
与官方公开系统提示词的显著差异,体现了信息的不一致性和不准确性,这种差异可能会导致用户的困惑和错误选择。
Anthropic官方确实会公布部分系统提示词信息,如AI助手的基本角色、行为鼓励(如使用 Markdown 语法)、对特定问题的探讨兴趣、知识截止日期及“扩展思考模式”等。

然而,这次泄露的约25000 Token提示词与官方精炼版本(可能2000-3000Token,不含完整工具细节)相比,差异巨大:
详尽程度悬殊:泄露版在安全规则、版权、工具调用、错误处理及边缘案例应对上远远超过公开版,后者更像概览性指南,前者则是详尽的内部操作规程。
工具指令透明度落差:官方通常不公开工具的完整定义、参数和内部MCP交互细节,但泄露版则揭示了这些“引擎盖下”的机制。
“内部运作逻辑”暴露:泄露版包含了更多官方秘而不宣的内部处理逻辑和“补丁式”规则,反映了模型长期的测试和迭代积累过程。
控制粒度与强度差异:泄露版通过海量指令构建精密决策网络,以实现高度精细化控制,其强度和覆盖面远远超过公开信息的体现。
综上,官方提示词更多扮演公关和基础透明角色,塑造简化正面的模型形象,而泄露的超长提示词则更真实地反映了,为确保模型安全、合规、稳定及用户体验,开发者采用的复杂“约束工程”,折射出AI公司在维护技术壁垒与满足社会对AI透明度需求间的持续博弈。

Anthropic忧,众人喜
Claude 的超长系统提示词意外泄露,不仅仅是技术圈的八卦新闻,它对 Anthropic 本身、甚至整个 AI 行业都带来了不小的冲击,许多人也开始重新思考模型安全、知识产权、以及“透明度”到底该怎么拿捏。
对Anthropic来说,这份提示词几乎是模型的“说明书+宪法”,经过精心打磨,既定义了模型该如何表达,也设置了安全边界和行为规范。被公开后,相当于把一部分“独门秘笈”摆在了竞争对手面前,让别人有机会研究、模仿甚至逆向还原,这多少会影响它的技术优势。
更为棘手的是,这份警示词就像模型的"安全护栏”,现在大多数人都了解如何搭建护栏,那些尝试“越狱”的人自然也容易找到绕开的方法。对Anthropic来说,这意味着需要面对更高的安全压力,并可能需要重新整理信息管理流程,以查找哪里出了问题。
从运营角度看,这种长提示词本身就是一个挑战——它占用了上下文窗口,计算成本也较高。泄露后,外界对 Claude 的技术路线和效率问题可能会有更多的疑问,甚至会促使它做出一些策略调整。
更微妙的一点是,Anthropic一直强调“负责任的透明度”,也曾部分公开过系统提示词。但这次泄露的版本明显更完整、更复杂,这让人们不得不问:Anthropic公开的“透明度”到底是真的吗?这种质疑对于一直打“安全、负责”旗号的公司来说,确实不是太好应对。

放眼整个行业,这份提示词意外变成了研究者的珍贵宝藏素材。它展示了顶级模型是如何被「教导」的,也让大家意识到:要让模型听话,靠几句话根本不够,这背后是一整套复杂、繁琐但极其重要的提示工程。
更重要的是,它再次提醒我们:AI 安全不是一劳永逸的成就,绕过它的技术也在同步进化,这是一场持续的博弈。
还有一个值得思考的问题是:这么长的提示词,其实说明现在的模型还没有办法真正“内化”所有的行为规范,必须依赖一堆外部规则来维持稳定。这可能会推动行业探索新的模型训练方式,减少这种“外挂式”控制的依赖。
尽管这次是一次意外,但从泄露内容中展现出的提示设计逻辑、安全框架,甚至对敏感话题的应对方式,也许会被许多同行借鉴,某种程度上也推动了行业形成了一些“非官方的最佳实践”。

在缺乏提示词的情况下,AI语言润色模型可以通过以下几种方法稳住: 1. 语义分析:通过对原始文本的语义分析,AI模型可以识别文本的主要内容、结构和 tone,从而确定需要润色的方向和范围。 2. 语言规则:AI模型可以根据语言规则和语法知识,对文本进行润色,例如,添加 connectors、修饰句子结构、改进词语选择等。 3. 语料库检索:AI模型可以检索语料库中的相似文本,寻找合适的语言模式和表达方式,然后将其应用于原始文本。 4. 学习与改进:AI模型可以通过学习和改进自己的语言润色算法,来提高对原始文本的理解和润色能力。 总之,AI语言润色模型可以通过语义分析、语言规则、语料库检索和学习与改进等方法稳住,提高对原始文本的润色质量。
Claude 系统的明显提示词泄露事件,让人群中的AI行业瞬间警觉:即使是系统再复杂、再精密,风险仍然是无处不在的。这不仅暴露了模型安全、透明度和知识产权的漏洞,也提醒大家,AI不是靠藏着提示词就能高枕无忧的。
为了走得更稳定,光靠封闭和保密已经不够了。模型本身需要具备更强的"免疫力",能够识别攻击、理解伦理要求,还需要减少对外部指令的依赖,更多地从内部"知道自己该怎么做"。否则,越长的提示词只会是一种临时的支撑,无法长期维持。
至于透明度,也不是越公开越好。如何在不泄密的前提下,让公众和监管知道AI是怎么运作的,这需要更细致的设计和行业共识。
AI发展太快,新问题一个接一个,迫切需要一套灵活的风险应对机制,能够及时识别问题、快速响应,而不是事后补救。
这次事件虽是意外,但它像一盏警示灯,提醒我们:AI的未来不能只靠技术的堆砌,还需要靠清醒的判断和持续的责任心。