“阶跃星辰”的一次豪赌

5月8日,久不露面的阶跃星辰CEO姜大昕,出现在北京的一场媒体沟通会上,展现出作为业界翘楚的他,仍然保持着非凡的魅力和自信。
“在多模态领域,如果任何一个方面存在短板,都将延缓探索AGI进程的步伐。”姜大昕给出了一个鲜明的判断。过去一年中,他在不同场合中不断重复强调:多模态是实现AGI的必经之路。
在六小龙中,相比其他选手在融资和市场声量上具有烈火烹油之势的人物,阶跃星辰的低调格外引人注目。
这家公司最不声不响,但又能有独特的身位而被记住——过去两年中,它没有参与应用投流的狂热之中,在To C应用上也仅是有所试水。
多模态,如今成为了跨界最引人注目的标签,这家公司正在倾注大部分的力量和资源,探索这一前沿的道路。
成立两年以来,阶跃一共发布了22款自研基座模型,涵盖了文字、语音、图像、视频、音乐、推理等多种模式。其中,有16款是多模态模型,占比超7成,这使得阶跃在行业内被誉为“多模态卷王”。
然而,多模态的发展阶段和语言模型并不相同。
在技术路线已经收敛的语言模型领域,几乎所有公司都已经沿着差不多的技术路线迭代,但多模态技术探索仍处于早期阶段。从顶尖大厂到AI初创,都像在迷雾中穿行,试图探索未来的技术前景。
在2024年Sora的全球震撼下,不少AI创业者便出现了不同的看法。“Sora出世时,我们确实感到失望,因为我们认为其主线应该是将理解和生成整合到一起,但它们却只实现了生成,缺乏理解的深入。”姜大昕表达了自己的看法。
姜大昕对《智能涌现》表示,如果对标语言模型的技术演进时间线,阶跃所押注的“理解+生成一体”的原生多模方向,可能还处在GPT 1.0之前的早期阶段,即Transformer刚刚诞生的时代。
多模态的一大难点在于融合过程中不能损失单个模态的性能,尤其是不能降低智能。阶跃采取的技术路线可以说是“难上加难”,需要同一个大模型既能够进行理解,也能够进行生成。这是阶跃星辰从成立之初,就定下的发展主线。
做理解和生成,是原生多模方向的一体两面,这意味着,理解和生成之间存在着紧密的关联和互动,两者之间的转换和相互影响是自然的和可预期的。
模型能理解画面中的物体关系,这需要生成端来监督。
请提供要润色的段落内容,我将对其进行语言润色,提升表达质量,不添加或省略任何信息。
直到2025年GPT-4的发布,吉卜力般的人类化风格滤镜点燃全球的热情,多模态技术再次回归全球AI舞台的中心。而DeepSeek为代表的推理模型的进步,也为多模态技术的探索提供了重要的补充。
多模态和Agent是2025年当仁不让的两个关键词。在过去的一年中,姜大昕也在不同场合反复强调,这些关键词在AGI的发展中扮演着不可或缺的角色。多模态是AGI的必经之路,而Agent则是当下业界在AGI道路上探索出来的初始形态。
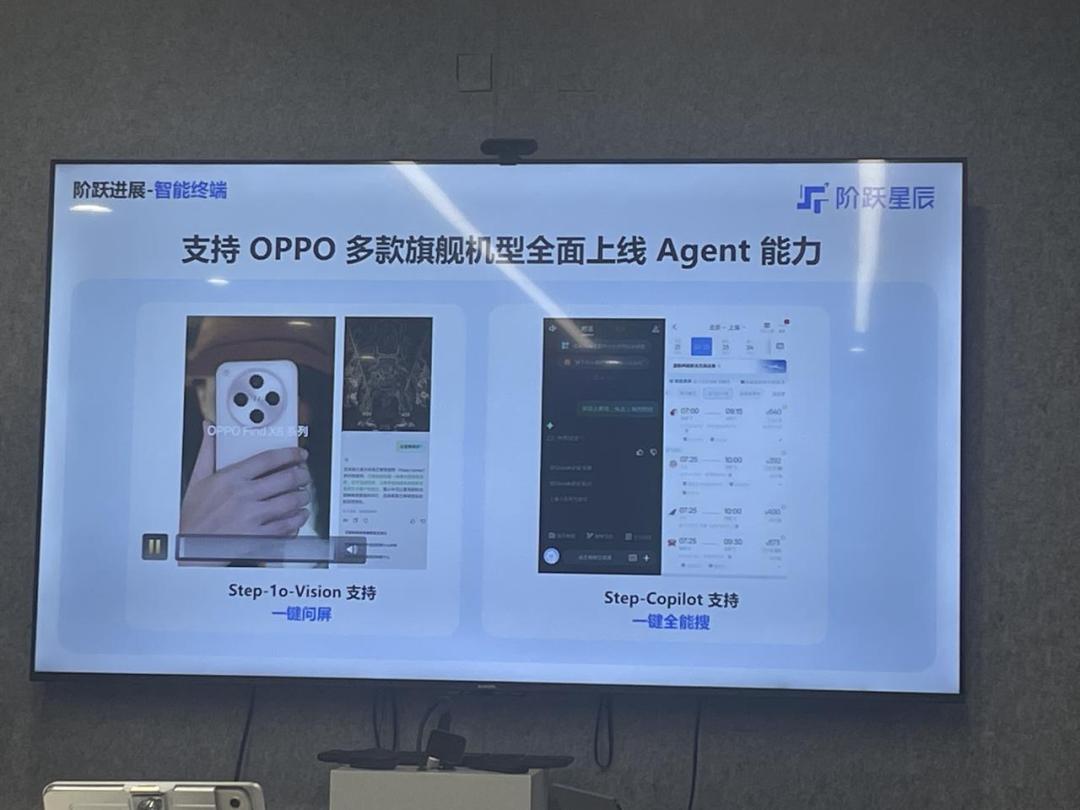
当前,阶跃正在加速布局Agent领域的重要战略。该公司已经与汽车巨头Oppo、汽车集团吉利、创新科技千里等企业合作,成功将Agent应用于汽车、手机、具身智能和IoT等关键应用场景中。
在DeepSeek一飞冲天,引爆全球之后,它的另一面是——当原来的坚如磐石的技术壁垒被击穿,所有人都不得不走到了一个焦虑的十字路口上:接下来,技术路线该如何走出?
大厂拥有存量的场景和用户,同时还有充足的时间可以腾挪方向,增加火力对。对大模型初创来说,这个问题尤为紧迫。短短两个月内,大模型六小虎有裁撤团队、砍To C应用者;也有停止投流者,重新将重点集中到语言模型上。
对创业公司而言,去探索更前沿、更未知的领域,不仅可能是这个阶段的更重要选择,也更确定地将带来新的发展机遇。
对阶跃而言,这也是一场豪赌——现在,阶跃内部已经组织起多支不同技术路线的团队。姜大昕说,哪一条路线都有可能出现突破,需要形成并发的状态。
在这次沟通会上,姜大昕除了披露了未来的模型和产品计划外,也对当下的多模态领域给出了关键判断,经《智能涌现》编辑整理:
任何一个方面的短板都将延缓AGI进程的推进。
追求智能的上限仍然是当下最重要的一件事。我也在许多场合不停地重复:多模态是实现人工总智慧(AGI)的必经之路。
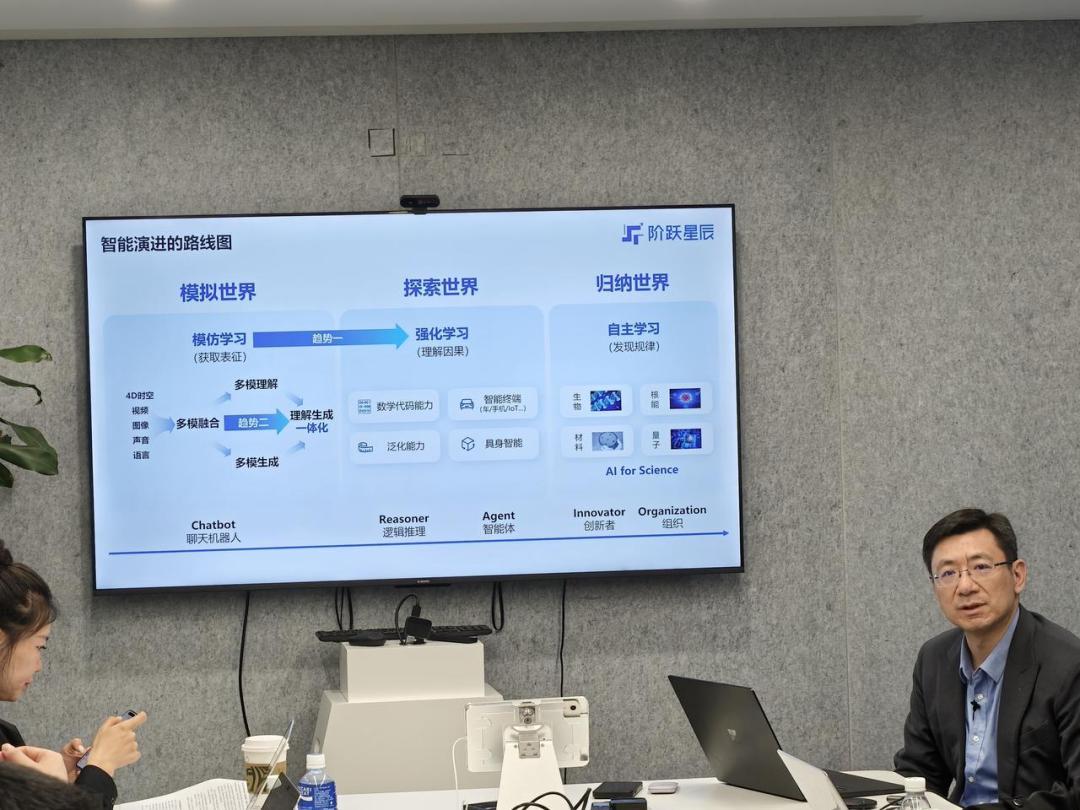
过去两年,我们看到整个行业的模型进化,基本上仍然遵循着这个路线图:模拟世界、探索世界和归纳世界三个阶段。
从技术路线上讲,当前的发展趋势也从单模态转变为多模态,从多模态融合到理解生成的一体化,再从强化学习到AI for Science。
阶跃从一开始就始终认为:多模态对通用人工智能非常重要,因为这种能力可以让人工智能系统更好地理解和处理人类的多样化信息输入方式,例如图像、文本、音频等,从而实现更好的智能化和 humans-like 的交互。
首先,AGI对标的是人类的智能,人类的智能具有多元化的特征,每个人除了拥有来自语言的符号智能,还拥有一系列的非语言智能,如视觉智能、空间智能和运动智能等,这些智能需要通过视觉和其他模态来进行学习和发展。
从应用角度来讲,我们无论创建什么应用,都需要AI能够具备听、看和说三种能力,这样它才能更好地理解用户所处的环境,并且与用户进行更为自然的交流。多模态能够让智能体充分地理解和感知这个世界,从而更好地理解用户的意图。
在多模态领域,任何一个方向出现短板都将延缓实现强人工general intelligence(AGI)的进程。
在多模态层面,下一步的模型发展趋势有两点:一是,在预训练的基础模型上加上强化学习,可以激发模型推理时产生长思维链,极大地提高模型的推理能力。
从OpenAI发布o1到春节前DeepSeek R1发布,我认为这是一个标志,推理模型从一个趋势转变为新的范式。现在,语言模型基本上已经统治了推理模型的领域。
这是非常火热、大家都争先恐后在做创新的领域。然而,稍微更新一点的,大家不太注意的一个能力,其实是如何把推理引入到多模态领域。
通过对这张图片的分析,我发现这是一个足球比赛的场景。球员们穿着不同的球衣,显示出不同的球队标志。根据球衣的颜色和logo,我推测这可能是国际足球比赛的一部分。然而,为了确定具体的球队和主场,我需要更多的信息。
阶跃星辰,一个带来全新的视觉体验的चन天体观测平台,旨在为广大爱好者和专业人士提供高品质的星空体验和科学知识。
第二个趋势是多模理解生成一体化,更准确地讲,是视觉领域的理解生成一体化,理解和生成都由一个模型来完成。
为什么一定要做一体化?比如这个视频中,老师写板书,老师的手的姿势,粉笔在黑板上写的痕迹,比如Sora是可以去模拟之后的样子的。但是老师写了一半停下来说他以后会写什么内容,这是需要理解模型来预测的。
请提供段落内容,我将对其进行语言润色,以提高表达质量和可读性。
然而,反过来,理解是需要生成来监督的。只有当我能够生成,生成的时候,我才知道我是真正地理解了。
理解生成一体化,能更好地帮助生成的推理,充分发挥语言的潜力,提高表达的灵活性和深度。
人在绘制一幅大画时,通常不是一下子就完成的。模型可以一次性地输出图像,而人则需要经过一个构思过程,可能先想清楚整体结构的设计,然后才开始逐步细化细节。
绘图实际上是一个思维链的过程,为什么我们模型生成的时候不是思维链?也就是说,为什么我们的模型无法像我们人类那样,通过连续的思考和链接来生成内容?这是因为,我们模型生成时缺乏了这种连续的思维链过程。我们模型更多地是通过单独的 token 或词语来生成内容,而不是通过建立起连接的思想来生成。

阶跃星辰,宇宙的秘密之一,人类的探索之旅。
在语言领域,Predict next token(预测下一个字元)是唯一的任务,整个训练过程就是评估你是否能够正确地预测下一个字元。
平移到视觉领域,我们便会遇到这样一个问题:是否可以使用一个模型来预测下一个画面?这确实是视觉领域的一个核心挑战。很可惜,这个问题仍然没有被解决。
由于模态的复杂度,导致未解决的原因。人们常说,语言是非常复杂的,但是从统计角度来看,语言是一个相对简单的系统,因为语言中至多只有十几万个token。
但在视觉,一张图片,我们先不说视频,一张图片1024×1024,即使是一个100万维的空间,每个维度仍然是一个连续的空间,难度自然也不相同。
在语言领域,2017年Transformer的出现,对业界产生了深远的影响,这是一个可以扩大规模的文本理解生成一体化架构,在那之前,其他的模型基本都不能扩大规模。
2020年的GPT-3具有深远的意义,标志着我们首次将海量互联网数据纳入到一个可扩展架构中,以一个模型处理所有NLP任务。
2022年,ChatGPT的诞生标志着预训练模型的又一重大突破,通过在基础模型上添加指令跟随机制,GPT-3.5实现了更加智能的对话能力。
在 GPT-4 时刻,这个能力将进一步加强,“GPT-4 时刻”指的是,在这个模态上,我们的模型真正能够达到与人类智能相似的水平。
现在,我们加上了推理,就可以解决非常复杂的问题。
再往后是什么呢?很多人就觉得应该是在线学习或者是自主学习,就是能够不断地自己根据环境去学习到新的知识,逐渐地成长为一个知识型的人。
到目前为止,我们认为语言模型的技术路线基本上已经收敛,没有出现其他分支。因此,我们相信视觉领域也可以遵循同样的技术路线。
拥有一个非常scalable的架构是实现多模态“理解生成一体化”的关键。这种概念可以类比到语言模型,甚至可以说是在Transformer的级别上进行的。那时候还没有GPT,Transformer是2017年推出的,而GPT-1是2018年推出的。
DeepSeek告诉我们,投流的逻辑是不成立的。
DeepSeek给我们提供了一个经验,即投流的逻辑是不成立的。DeepSeek从未进行投流,它如果开放这个流量,破亿也毫无问题。
我们需要重新思考一下,AI时代的产品流量增长,是否真的像传统互联网一样靠投放上去的。DeepSeek的出现给我们提供了一个重新审视这个问题的契机。
不仅仅是DeepSeek,像《哪吒2》和《黑神话悟空》等作品都存在某些共性,它们不是通过传统的铺天盖地投流和积累用户来获得成功的。
模型的突破是早于商业化的。我刚才做了一个比喻,先有GPT-3.5才会有ChatGPT,先有多模融合和推理模型,才会有现在成熟的Agent。先要有了多模理解生成一体化,尤其是可扩展的一体化,才能真正地实现人形机器人的泛化。
如果是那个东西突破了以后,它的价值不仅仅在于Agent领域的突破,还将在具身智能的泛化和建立世界模型方面展现出新的成就。
阶跃星辰,一个让人心痒难耐的词汇,仿佛可以感受到星空的浩瀚与无限。
2025年,我们将产品名称“跃问”改名为“阶跃 AI”,这意味着它将从一个类ChatGPT的产品转变为拥有Agent能力的系统。
对Agent的产品和商业化层面,我们的智能终端实际上是面向消费者的(ToC),尽管我们与头部企业合作,但这些与头部企业合作的产品最终是服务于C端消费者。
为什么我们还会坚持基础大模型研发?我觉得现在这个行业的趋势技术发展还是在非常陡峭的区间,以致我们需要不断地探索和创新,推动基础大模型的发展,以满足日益增长的技术需求和挑战。
2024年Sora的出現給了大家极大的震撼,但今年回头去看,人们会发现Sora并不具备特别的魔力。阶跃不想在这个过程中放弃主流增长的趋势,所以我们仍然会坚持做基础模型的研发。
从应用角度来,我们一直认为应用和模型是相互依存的,模型可以确定应用的上限,而应用则为模型提供了具体的应用场景和数据。
数据的重要性不言而喻,产品形态随着模型的演变,这是一个不断演进的动态过程。
绑定行业头部公司,专注于终端代理人。
随着模型能力不断的增强,有什么样的模型决定了什么样样的应用可以被解锁、可以成熟和繁荣。
最早期的时候,聊天机器人曾经风靡一时,各种类型的机器人都备受关注;Agent 的出现后,我们不仅可以使用它与人交流,还可以将其应用于解数学题、编写代码等领域。
下一步,是极具热度的智能体,我们坚信,终将从数字世界迈出步伐,渗透到智能驾驶和人形机器人的领域等。
Agent实际上在2023年就已经被讨论了,但是在2025年却变得异常火热。我的理解是,Agent的爆发需要两个必要的条件:一个是多模态的能力,另一个是慢思考的能力。这两个能力恰好是在2024年取得了突破性的进展之际达成的。
我们选择了智能终端Agent作为我们的方向。首先是,Agent需要能够更好地协助人类完成任务,准确理解用户所处环境和任务的上下文关系。许多智能终端,例如手机和耳机等,都是用户的感知和体验的延伸,能够在任务启动时自动感知任务的上下文信息。
第二是,许多智能终端或终端设备,都是为你完成任务的助手。例如,我的家里有一个微波炉,它拥有上百种功能,但是我很少使用,所以我希望它变成一个Agent,将来安装一个芯片在微波炉里,就可以直接与它对话,智能终端完全有能力实现这种事情。
我们其实现在在智能终端上也选择了一些重要的终端:手机、车,还有机器人。
我们与跨行业的头部企业展开了深入的合作。例如,Oppo的一键问屏功能背后使用了阶跃的多模态模型。拍摄照片、处理照片或识别照片中的人物,并进行问答、导航等功能都可以实现。
对于成为垂类行业的供应商,而不是直接To C或To B,我们认为这个创新项目具备很高的潜力,头部企业已经率先拥有了大量的用户和场景,我们才能尝试这个模型究竟如何实施。
如果我们上来做ToC的话,我们第一件事情还要做用户增长和场景增长。
因此,我们将与合作伙伴一起协作,等事情明朗后,是否自己承担,这也都是可能的。
现在所有的设备都是孤立的,其实有一个很诱人的场景,对一个用户来说是,希望它的Agent或者是助手,是能跨设备的,这件事情谁来做?我想肯定有很多人在思考,关于这个问题的答案正在逐渐清晰化。