强化学习之父当头一棒:RL版“苦涩的教训”来了!通往ASI,绝非靠人类数据

编辑:编辑部 XJZ
【新智元导读】强化学习之父Richard Sutton和DeepMind强化学习副总裁David Silver发出了震撼的警示:人类已经从数据时代迈进了经验时代。要实现ASI的目标,不是靠人类数据,而是靠强化学习!
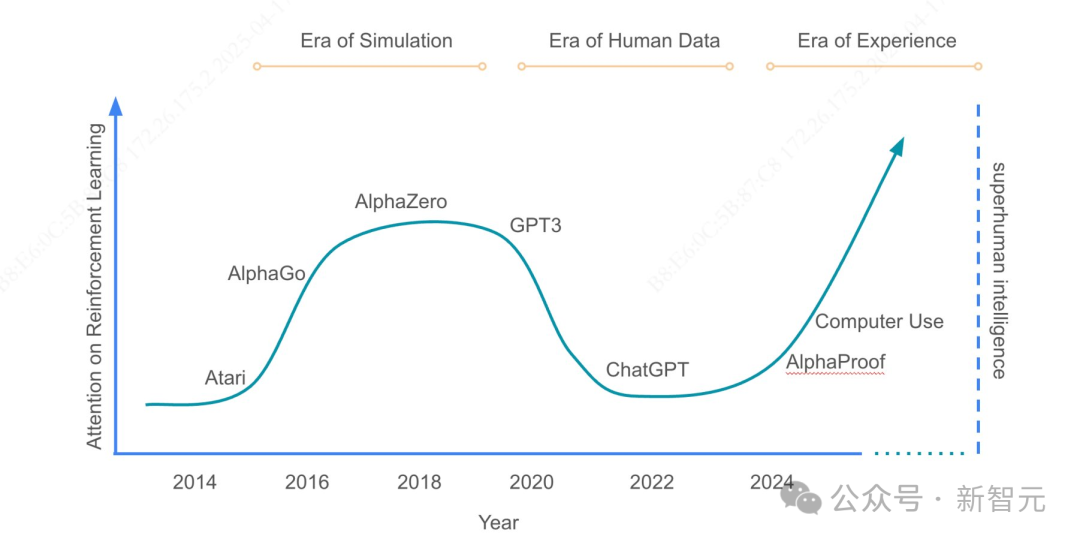
最近,图灵奖获得者、强化学习之父Richard Sutton,联同DeepMind强化学习副总裁David Silver共同发布了一篇文章。

有人称,这篇文章就如同《The Bitter Lesson》的续章,给了我们当头一棒——AI范式正在经历大转折!
我们经历过模拟时代,享受过人类数据时代,如今正踏入经验时代。
为了真正发展AI,不是靠模仿,不是靠学习,而是靠「活过」!
请提供需要润色的文本,我将对其进行语言润色,提升表达质量。
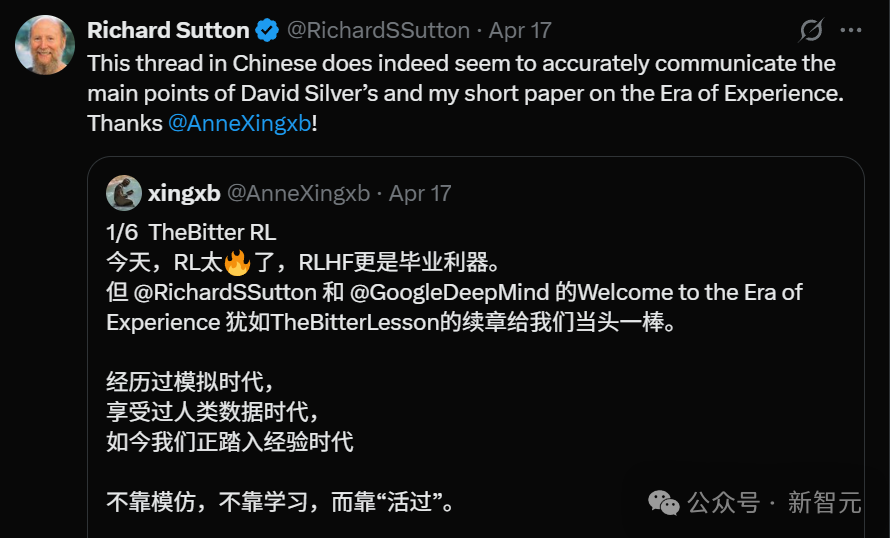
一位中国网友的总结,获得了RL之父本人的转发和赞许。
请提供网页中一个段落的内容,我将对其进行语言润色,提升表达质量。
我们正从「人类数据时代」跨入「经验时代」。这不是模型升级,不是RL算法迭代,而是一种更根本的范式转折:
从模仿人类到超越人类,人类的技术和思想不断进步,探索未来的可能性。
从静态数据到动态经验:数字时代的数据化转变。
从监督学习到主动试错:在智能系统的演进中,我们逐渐从监督学习转变为主动试错。监督学习的缺陷在于需要大量标注数据,且模型仅能复制已知的模式,而无法解决未知的问题。相比之下,主动试错的方法可以让系统自己探索和学习,从而更好地适应未来的挑战。
他们喊话整个AI界:经验是通往真正智能的钥匙!
人类数据正在见顶。今天的AI(如LLMs)依赖海量人类数据训练,它们能写诗、做题、诊断,几乎无所不能。然而,我们必须注意的是:
高质量数据正在枯竭。
AI的模仿能力已经逼近人类的上限。
· 数学、编程、科研等领域再难靠「喂数据」进步,需要深入挖掘领域内的规律和规则,进行理论的创新和探索。
因此,模仿能让AI胜任,但不能让AI突破。
而经验正是下一个超级数据源。真正能够推动AI跃升的数据,必须随模型变强而自动增长。唯一的解决方案,就是经验本身。
经验是无限的。
· 经验能突破人类知识边界,开启人类智慧的新天地。
· 经验流才是智能体的本地语言。
因此,RL之父的主张是:未来AI不是「提示词+知识库」,而是「行动+反馈」的循环体。
它们有几个关键特征:高效、智能、可靠、安全和可扩展。
· 他们生活在持续的经验流中(非任务片段)
· 它们的行为扎根于真实环境,不靠聊天框。
奖励来自环境,而非人类打分。
· 推理依赖于行动轨迹,而非仅模仿文本逻辑。
这些都是对LLM范式的一次根本性挑战。
强化学习并不能解决所有问题,如今,我们的经验智能仍然处于初期阶段,但技术条件和算力已经具备。AI社区是否准备好,拥抱主动智能范式?
这将是一次思想上、技术上和伦理上的深刻转折。
通往ASI:经验时代的新阶段
最近,DeepMind强化学习副总裁David Silver掀起桌子,大声宣言——
大语言模型(LLM)并非人工智能(AI)的全部!
人类需要的是能够独立推理、探索未知领域的AI。
那么,如果剥离人类反馈的要素,最终得到的模型还能保持现实根基吗?——探索人工智能在认知和感知中的边界。
David Silver提出了与主流相反的观点。

在近期的博客中,他探讨了「经验时代」与当前「人类数据时代」的概念,展开了深入的讨论。
以AlphaGo和AlphaZero为例,他强调了强化学习的潜力,可以超越人类能力,而不需要先前的知识和经验。
这种做法与依赖人类数据和反馈的大语言模型形成鲜明对比,前者主要靠算法和规则来生成语言,后者则是通过人类的实时反馈和调整来提高语言的质量和逻辑性。

Silver 强调探索强化学习对于推动人工智能(AI)进步和实现全自动智能系统(ASI)的必要性。
在当前多模态模型的热议、兴奋和成就的后续发展中,David有一个通往ASI(Artificial Super Intelligence)的计划,他称之为「经验时代」的新阶段。
「经验时代」将与过去几年的差异,完全不同。
过去,一直处于「人类数据时代」的阶段,也就是说,所有AI方法都共享着一个共同的设想:
提取人类拥有的所有条知识,然后输入到机器中,以实现人工智能的巨大飞跃。
这固然非常强大。
然而,还有另一种方法,它将引领人类进入「经验时代」,即机器与实际世界本身互动,并产生自己的经验。
如果将交互数据视为驱动机器的燃料,那么这将引领下一代AI的进入「经验时代」,标志着人工智能的发展驶入了一个崭新的阶段。
在某种程度上,David是拍案而起,大声疾呼:「大语言模型并非唯一的AI,」他的声音激烈、响亮,带着对这个观点的强烈认同和坚持。
也就是说,人工智能(AI)还有其他选择,可以用不同的方式来实现强人工智能(AGI)。
构建大语言模型,AI 的确获益良多,通过不断学习和改进,它们能够捕捉到更加复杂和多样化的语言模式,从而提高语言理解和生成的能力。
通过发掘海量的人类自然语言数据,将所有人类书写过的知识悉数整合进机器之中。
然而,人类似乎需要跨越这个阶段:超越认知的限制。
要实现这一点,就必须采用全新的方法——重新定义传统的生产关系和组织形式,推动企业的创新和发展。
这种方法要求AI能够自主推理,发现人类未知的领域,激发科学家的创新精神和探索精神,从而推动人类知识的发展和进步。
这将开启一个全新的AI时代,标志着人类社会的历史性转折点,它必将为社会带来前所未有的深刻变革与无限可能。
AlphaGo:与LLM完全不同,前者是一种基于深度学习和树搜索的游戏智能系统,旨在模拟人类棋手的思维和动作,实现人机对弈的胜负之争;而LLM则是一种语言模型,旨在模拟人类语言的生成和理解能力,实现语言的生成和理解。
与LLM不同,其他的一些著名的AI模型采用了不同的方法,最值得一提的是AlphaGo和AlphaZero,这两种AI模型的出现标志着人工智能领域的重大突破。
大约十年前,它们曾经击败了世界上最顶尖的围棋选手。

AlphaGo以惊人的速度和准确性击败了当时的围棋国际排名第一位柯洁,这标志着人工智能在围棋领域的突破性成就。
如果您想从头开始学习围棋,首先需要了解围棋的基本规则和术语。围棋是一种策略性游戏,需要您具备一定的逻辑思维和空间想象能力。下面是一些建议,帮助您从头开始学习围棋: 首先,您需要了解围棋的基本规则,包括棋子的移动、吃子、活子、死子、平手和胜负的判定等。可以通过阅读围棋的规则书籍或在线资源来学习这些基本规则。 第二步,您需要学习围棋的基本术语和概念,例如“ Liberties”、“Ko”、“Seki”等。这些术语和概念是围棋游戏的基础,您需要理解它们的含义和应用。 第三步,您可以开始学习围棋的基本策略和技巧,例如“ Opening”、“Middle Game”和“Endgame”等。这些策略和技巧可以帮助您更好地控制游戏的进程和提高您的围棋水平。 第四步,您需要实践和训练围棋。可以通过在线游戏平台或与他人对局来实践和训
特别是 AlphaZero,它与最近基于人类数据的方法存在着明显的不同,因为它完全不依赖人类数据。

「Zero」(零)这个词就代表了这一点。因此,系统中预先编程的是字面意义上的零,人类知识的起点。
LLM的替代方案是什么呢?如果不复制人类,并且事先并不知道正确的下棋方式,如何学习围棋知识呢?LLM的替代方案之所以能够学习围棋知识,是因为它们可以通过自适应学习和数据分析来模拟人类的下棋思维和经验。它们可以通过分析大量的围棋比赛和游戏记录,学习到围棋的规则、战略和 tactics,从而逐渐提高自己的下棋水平。
可以采用的方法是一种试错学习的形式,通过不断的尝试和反馈,可以逐渐地提高语言表达的准确性和流畅性。
AlphaZero自我对弈了数百万局围棋、国际象棋或它想玩的其他棋类游戏。
渐渐地,它发现:「哦,如果在这种情况下下这种棋,那么我最终会赢得更多的比赛。」
通过这次的挑战,这变得更加强大了。
随后,它会微微多下一些类似的棋,下一次它会发现一些新的东西,它会说:“哦,当使用这种特定的模式时,我最终会赢得更多的比赛或者输掉更多的比赛。”
这将反过来促进下一代的学习,以此类推。
这种基于经验的学习,通过智能体自身产生的经验来学习,就足够了。
虽然最初版本的AlphaGo确实以人类数据为起点,但这并没有限制了它的能力,反而是促进了它的发展。
该数据库学习并吸收了人类职业棋手的棋谱,这为它提供了一个起点,吸收了人类的经验和智慧,逐渐形成自己的棋风和战略。
从那时起,它通过自己的经验和实践进行了自我学习和完善。
然而,一年后发现,人类数据并不是必需的,可以完全抛弃人类的招法。
这份证明表明,程序不仅能够恢复到之前的性能水平,而且实际上表现出更加出色的性能,并且能够比最初的AlphaGo更快地学习,从而达到更高的性能水平。
苦涩的教训:人类数据的价值可有可无。
AlphaZero的行为显得非常奇怪:它抛弃了人类数据,结果发现人类数据不仅没有什么实质性贡献,而且在某种程度上还限制了其性能。
这涉及到AI领域深刻的「苦涩的教训」。
人们普遍认为:人类累积的知识具有极其重要的价值。
这导致设计的AI算法可能更适合人类数据,而不太擅长自主学习。
然而,结果是,如果抛弃了人类数据,实际上会花费更多的精力让系统自主学习。
只有通过自主学习,我们才能不断地学习和学习,实现由此而来的螺旋式上升,永远拥有学习的渴望和热情。
这几乎就是承认AI可能比人类更擅长下围棋,且在某种程度上突破了人类的上限。
人类数据对于AI的起步非常有用,但人类所做的一切都存在一个明确的上限。
在 AlphaZero 中,人工智能通过自我对弈的方式进行学习,逐渐提高其能力,终于超越人类的极限,远远超过人类的水平。
在「经验时代」,人类终于找到了一种方法,可以在所有领域中突破传统的限制。
以灵感为指南,AI神来之笔:第37手,展现出一种新的创作方式,融合了人工智能和艺术家的想象力,开启了一种全新的尝试。
AlphaGo对阵李世石的第二盘棋中的第37手棋,出乎所有人的意料。
AlphaGo落在了第五线上,以某种方式下出了这步棋,导致棋盘上的一切变得井然有序。
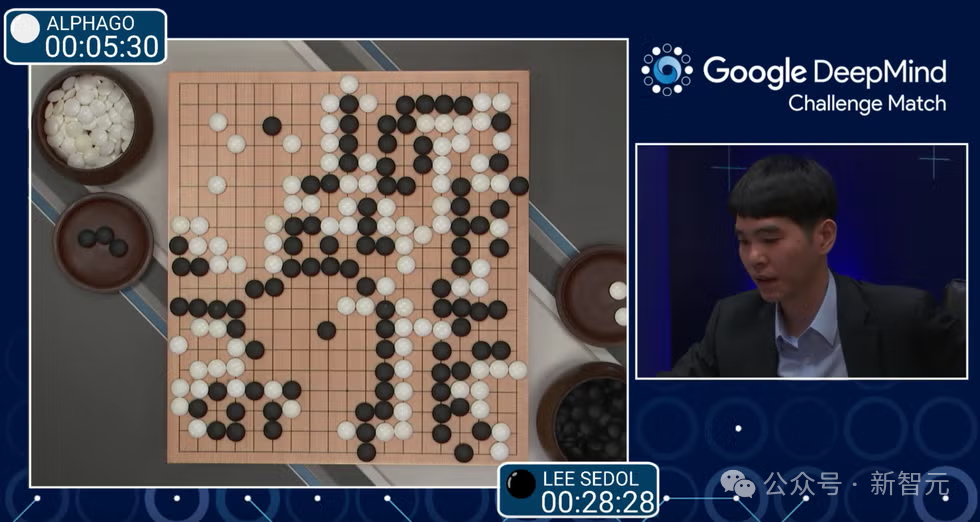
对人类来说,这是一个如此陌生的步骤,人类想象一下这步棋的可能性只是万分之一。
人类对这步棋感到震惊,然而它却帮助AlphaGo赢得了那盘棋。
在那一刻,人类突然意识到:「看,这里发生了一些开天辟地的事,机器竟然想出了一些与人类传统思维方式迥异的下棋方式」。
这是历史性巨大的进步,远超出人类知识的界限之外。
因为人类长期沉浸在数据时代,投入了大量精力来模仿和复制人类能力,而鲜有关注超越人类能力的前沿探索。
除非真正强调系统自主学习,超越人类数据,否则不会在现实世界中看到像第37手棋那样巨大的突破。
第37手棋不仅仅是一个单一的发现,而是证实了从经验中不断地学习和探索的结果,涌现出无穷的发现和潜力。
刚刚完成国际象棋上的AlphaZero,直接将其应用到将棋(日本象棋)的游戏,结果连世界冠军都认为远超人类的上限。
实际上,这是AlphaZero第一次在将棋上运行的尝试。
开发者只是按下了「开始」键,一个超人的将棋选手突然诞生了。
与魔术般地巧合。
强化学习(Reinforcement Learning)是一种机器学习算法,旨在通过与环境的交互来学习如何采取最佳的动作,以达到特定的目标。强化学习中,智能体(Agent)通过探索和试验来学习环境的反馈机制,逐渐掌握如何实现目标。
甚至机器可以自己设计强化学习算法,DeepMind已经过多年的研究。
他们构建了一个系统,通过自我试验和不断的强化学习,逐渐发现哪种算法最适合其强化学习的需求。
它学会了如何构建自己的强化学习系统,通过自主学习和探索,逐渐掌握了复杂的算法和数据结构,实现了智能决策和自动优化。

令人难以置信的是,它实际上已经超越了人类提出的强化学习算法。

论文链接:https://arxiv.org/abs/1805.09801
这又是一个反复出现的故事:随着人类因素的不断介入,它的表现反而越差。将人类因素排除出去,它反而能展现出更加出色的表现。
当前,强化学习已经广泛应用于所有类型的LLM系统中,主要是通过与人类数据的结合使用来实现。
与AlphaZero的方法不同,这意味着强化学习实际上是通过人类偏好来进行训练的。
这被视为基于人类反馈的强化学习(RLHF),在大型语言模型(LLM)中发挥着非常重要的作用,是一个巨大的进步。
然而,David Silver认为RLHF的缺点同样明显:
这是把洗澡水和孩子一起倒掉了。
基于人类反馈的强化学习系统(RLHF)展现出强大的能力,但它们尚未超越人类的知识边界。
如果人类不知道某种新想法,并且低估了某些行动,那么系统就永远无法学习找到最佳行为。
这就像人类在预先判断系统的输出。
从这个意义上说,它是一种不可靠的依据。
只有通过这种可靠的反馈,系统才能不断迭代和探索, ultimately discover new and innovative things。
人类数据是基于人类经验和知识的 accumulate。
因此,LLM继承了人类从实验中发现的所有信息。
然而,在一些领域,人类数据根本不存在。
系统需要通过它自己的实验、试错和可靠反馈来自己弄清楚,这是探索和自我完善的必经之路。
合成数据的出现有助于解决数据匮乏的问题。
然而,与从人类数据中获得的上限类似,无论这些合成数据有多么出色,它们都会达到阈值,即这些合成数据不能让系统变得更为强大。
而自我学习系统将不断生成能够解决它正在遇到的下一个问题的经验。
这就是使用自我生成的经验与合成数据之间的区别。
在许多领域中,自我生成大量的数据经验是件不可能的事情。
RLHF只能够让系统学习选择人类更偏好的策略。
如果在AlphaGo中使用RLHF,它最终不会下出第37手棋。
由于它只会按照人类的认知方式下出棋局,而永远不能发掘人类未知的下棋方法。
在其他领域中,这也具有深远的意义,例如在数学领域中。
「17岁的数学天才」
数学,这个神秘和深邃的领域,经过几千年的探索和钻研,人类取得了令人难以置信的成就。
AI能否达到人类经过多年努力所达到的相同水平?这是一個有趣的問題,讓我們探討人工智能的發展前景。虽然人工智能已经取得了许多進步,但仍然存在一些人类难以企及的领域。例如,人类的情感intelligence、社会交往能力、創造力等方面,AI还需要繼續发展和完善。然而,AI在某些領域,如數據处理、计算机视觉、语言处理等方面,已经超出了人类的能力。因此,答案是:AI能够达到人类经过多年努力所达到的相同水平,但不是在所有领域,需要继续发展和完善。
AlphaProof,一个基于经验的系统,旨在证明数学问题的可靠伙伴。
有趣的是,AlphaProof与现在的LLM工作方式完全相反!
LLM倾向于大量生成幻觉(hallucinate),它们会编造出虚构的内容。
如果要求LLM证明一个数学问题,它们通常会输出一些非形式化的数学内容,然后还要告诉你「相信我,这是对的」,这使得用户难以确信其正确性和可靠性,特别是在数学领域中,证明的准确性和可靠性是非常重要的。

然而,实际上,有可能是对的,也有可能是错的。
AlphaProof的优势在于其独特的AI算法,可以实时检测和防止各种形式的不正当行为,包括人工智能生成的虚假内容、自动化的采样和复制、人工智能生成的虚假评论等。AlphaProof能够准确地识别和拦截这些不正当行为,保护用户的隐私和权益,同时也提高内容的可靠性和可信度。
DeepMind推出了一个全新的数学语言-"Lean"-,旨在将数学定理和问题进行形式化,开启了数学研究的新篇章。
可以想象一下,普通的LLM使用的是自然语言,人类文本;然而,这种新的数学语言却具有独特的逻辑结构和符号系统,它能够以更加严格的方式表达复杂的数学概念和关系。
本质上,AlphaProof在确定定理的证明是否正确,以及AlphaGo在棋盘上实现输赢一样,都是基于算法的决策过程。
David Silver进一步举了一个例子,即DeepMind使用了相同的AlphaZero代码来提高围棋、国际象棋和其他游戏的水平。

同样,可以把代码用在数学问题上。
这也让作为数学教授的女主持人惊呼:"你们怎么敢!"
国际奥林匹克数学比赛,每年的挑战者都是来自世界各地的年轻天才数学家。
AlphaProof取得了银牌成绩,这是全球仅有的10%人群能够达到的成就。
很好奇,如果完全没有人类的数据输入,AlphaProof的证明看起来是什么样子?是遵循人类风格的论证方式吗?AlphaProof的证明将是一种高度机械化、逻辑严密的过程,完全依靠算法和数据来推理和证明结论,而不是人类的直觉或经验。这种证明方式将是严格的、循规蹈矩的,遵循严格的逻辑规则和数学公式,并且不受人类的情感、偏见或错误影响。
David承认,他无法真正地理解那些复杂的证明过程。

DeepMind迎来了一位大神,Timothy Gowers,菲尔兹奖得主、前IMO选手和IMO的多枚金牌得主,备受尊称的超级大脑(Mega brain),被誉为天才中的天才。
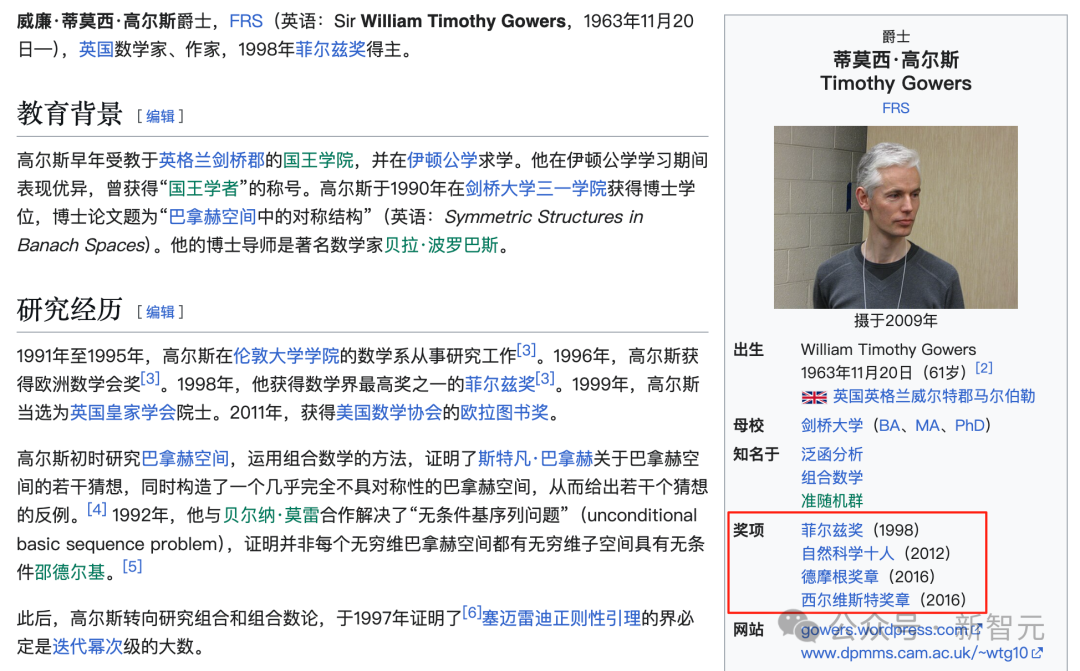
Timothy Gowers实际上就是AlphaProof的裁判。
英国数学家Timothy Gowers认为,AlphaProof在数学上的能力是一个巨大的飞跃。
David将AlphaProof称为是一个「非常、非常、非常有才华的17岁数学家」,但最终我们想要的是一个「数学天才」。
这条路在刚刚开始。
克莱数学研究所在2000年为七个不同的数学问题提供了百万美元的奖金。
人类数学家已经耗费了四分之一世纪的时间来尝试解决这些数学难题,现在终于有一个被攻克了。
David认为,下一个大挑战很有可能就会被人工智能(AI)解决。
因为如果有一个系统可以不断地学习、学习、学习,那么它的上限将是无限的,你可以想象这些系统在5年、10年、甚至是20年后的样子,具备着前所未有的智能和能力。

数学还有一个特点,即数学可以形式化、符号化,是完全可以通过人工智能(AI)与人工智能交互而不断前进的领域之一。

经验如何泛化到混沌系统?在混沌系统中,经验的泛化问题变得尤为复杂和挑战性。由于混沌系统的不确定性和随机性,经验的泛化需要考虑到系统的非线性和随机性特征。因此,需要发展新的泛化算法和方法,以适应混沌系统的特点。
要么赢得一局围棋,要么没有。
数学证明要么是正确的,要么不是。
然而像AlphaZero、AlphaGo和AlphaProof这样的系统,经验如何泛化到一个没有明确的「获胜」指标,并且更加混乱的系统?其挑战在于,系统需要学习如何在没有明确目标的情况下,发现和适应新的规律和模式,从而在不确定的环境中取得进步。
David说,这个问题其实就是为什么强化学习方法或者这类基于经验的方法,尚未打入所有主流AI系统中的原因。
然而,David也强调了,人类也许指定他们想要什么,比如我想更健康,这种很“模糊”的目标转化为更量化的数字。
将「转化为」改为「转换为」,以提高语言的流畅性和表达性,润色后的内容如下: 比如你想更健康,可以转换为静息心率或BMI等这些指标的集合,可以被用作强化学习的某种奖励。
并且只需要少量的数据就可以让系统为自己制定目标,因为这个目标可以是一个随着时间推移而自适应的数字组合。
指标暴政(tyranny of metrics),一种隐形的压迫力,潜伏在我们身边,影响着我们的决策和行为。
将量化指标作为衡量成功的标准——强化学习的「奖励函数」——是否会导致一些无法预料的问题?这种基于数值的评估方式可能会忽视复杂的问题的多样性和不确定性,进而引发一些无法预料的问题,例如,奖励函数的设计可能会鼓励某些短期的优化,而忽视长期的后果,或者导致过度依賴某些特定的指标,忽视其他重要的指标。
讨论中用一个词语,指标暴政来形容这种现象。指标暴政是指在经济发展过程中,经济指标的日益重要性和尝试对其进行微观调控的恶意行为。
学生不断追求更高的考试分数,或者国家追求更高的GDP,这种单一化的目标驱动力,可能会导致个体和集体专注于目标,以至于忽视其他重要方面的发展。结果,这些个体和集体很难再优化这个目标,往往就是为了这个目标而不择手段。
在人类世界中,盲目追求一个指标时,它往往会导致不希望的后果。
一个小小的奖励,是否足够?它让我们感受到生活的美好,激发我们继续努力,但它也不能代表我们所有的付出和努力。
在前一期的采访中,David曾撰文表达了自己的立场,即“Rewar is Enough”,这与当前的LLM技术发展道路选择存在着明显的差异。

论文链接:https://www.sciencedirect.com/science/article/pii/S0004370221000862
强化学习正是通往AGI(通用人工智能)的必经之路,David仍然坚信这样一个想法。
他举了个例子,当前人类依靠的LLM就像地球上的化石能源,总有一天会被消耗掉的。
然而基于强化学习的系统,则是一种可持续的能源——它可以不断生成、使用和学习,逐渐累积经验,从中获得更多的知识,并不断地从中学习。
当然,David 表示,当前的LLM已经非常出色,当前的AI也让人感到惊叹,难以置信的技术成果。
然而,当你停下来思考时,围绕AI讨论的思想多样性确实在收窄。
人们不断地讨论LLM,LLM却不断地超出人们的预期。
关于大模型的讨论已经吸走了我们在讨论AI时的过多的「氧气」。
然而,目前也出现了一种声音:我们已经达到了可用的人类数据极限。
但就像David所说的一样,如果我们想要追求一种可持续的「智能能源」,
如果我们真正渴望超越人类智能,那么现在也许是时候摆脱人类(数据)的束缚了。